『深度学习』动手学深度学习——阅读笔记1
『深度学习』动手学深度学习——阅读笔记1
❀目录❀
零. 前言
动手学AI电子书链接。本书阅读于24年寒假,每天上午一章节,随阅读随记录笔记,记录的不详尽或复制粘贴原文之处敬请谅解。By the way,这是笔者推荐深度学习入门最好的指导书。
一.引言
1. 四大基石
数据
模型
目标函数
优化算法 —— 基于梯度下降
2. 机器学习分类
- 有监督学习(分类,回归,序列学习—时间序列预测),下流任务丰富多样
- 无监督学习
- 强化学习(环境—动作—奖励 三元组)
二. 数学基础
1. 线性代数
数据形式
标量
向量
矩阵
张量
运算
矩阵元素级别运算
向量间点积
矩阵 * 向量
矩阵 * 矩阵
范数:衡量向量的“大小”
L1
L2(欧氏距离)
余弦距离
2. 微分
构建计算图来保存每个标量在反向传播后的梯度,梯度的计算运用偏导和链式法则。
梯度:中对每一个自变量x分值的微分,结果为一个向量
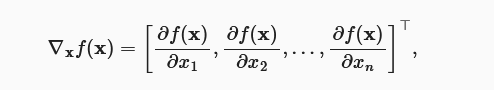
链式法则:见淑芬
分离计算图:y.detach() 将y从计算图中分离,将其看为常量,不会在经过y向后传播到其他参数。
一般而言,函数都是”多对1”的,即向量到标量的映射,向量到向量的映射也可以被拆解为多个向量到标量的映射。
torch 支持自动微分,详细请参见mlsys部分。
3. 概率
随机变量,条件概率,联合概率,Bayes定理,期望与方差。
三. 线性神经网络
最简单的单层网络结构。
1. 线性回归
拥有解析解,可通过牛顿最小二乘等方法求解,然而更多的深度网络没有解析解,而只能通过梯度下降逼近的方式逼近最小值。
2. 全连接层
最基础的线性模型。
3. softmax
激活函数,无参数,用于分类,即使不是线性变换,但也是输入经过仿射变换得到,因此也是线性模型。

在pytorch实现中,我们没有将softmax概率传递到损失函数中, 而是在交叉熵损失函数中传递未规范化的原始预测,在内部计算softmax及其对数, 这是一种聪明方式。
4. 仿射变换的概念
相比之下,仿射变换是一种线性变换,它包括缩放、旋转、平移和切变等操作。在神经网络中,通常所说的仿射变换通常指的是某层的输出是输入的加权和加上偏置项,数学上表示为:
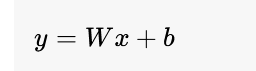
四. 多层感知机
深层网络的基本原理与技巧。
1. 训练误差与泛化误差
训练误差(training error)是指, 模型在训练数据集上计算得到的误差。 泛化误差(generalization error)是指, 模型应用在同样从原始样本的分布中抽取的无限多数据样本时,模型误差的期望。
2. 欠拟合与过拟合
欠拟合:表现为训练误差和验证误差都很严重, 但它们之间仅有一点差距,意味着模型表达能力不足,无法学习模式,但是我们有理由相信可以用一个更复杂的模型降低训练误差
(重点)过拟合:模型在训练数据上拟合的比在潜在分布中更接近的现象称作过拟合,即训练误差很低,但是训练误差与泛化误差的差值较大,解决过拟合的方法称为正则化
3. 影响模型泛化的三个因素
- 可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。
- 参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
- 训练样本的数量。即使模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
4. 正则化技术
在模型训练技术上提高泛化性的技术,经典泛化理论认为,为了缩小训练和测试性能之间的差距,应该以简单的模型为目标。何为简单:
权重衰减法:函数约接近0越简单,即令在损失函数中添加正则惩罚项,令权重尽可能趋于0。

暂退法(dropout):平滑性,越平滑越简单,函数越能对输入的微小变化不敏感越简单。因此每轮会令部分神经元置0。注意在测试时我们使用完整的模型,不使用dropout。
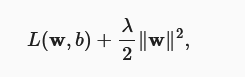

5. 训练过程
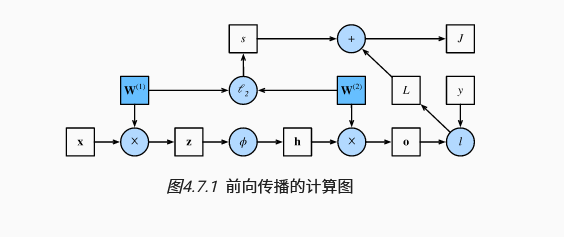
在训练神经网络时,在初始化模型参数后, 我们交替使用前向传播和反向传播,利用反向传播给出的梯度来更新模型参数。 注意,反向传播重复利用前向传播中存储的中间值,以避免重复计算。 带来的影响之一是我们需要保留中间值,直到反向传播完成。 这也是训练比单纯的预测需要更多的内存(显存)的原因之一。 此外,这些中间值的大小与网络层的数量和批量的大小大致成正比。 因此,使用更大的批量来训练更深层次的网络更容易导致内存不足(out of memory)错误。
6. 权重初始化
- 梯度消失和梯度爆炸是深度网络中常见的问题。在参数初始化时需要非常小心,以确保梯度和参数可以得到很好的控制。
- ReLU激活函数缓解了梯度消失问题,这样可以加速收敛。
6.1 默认初始化 / Kaiming 初始化
使用标准正态分布来初始化权重值。
6.2 Xavier初始化
仍然假设采样的分布应为零均值,方差$\delta^2$,并且假设在一个不存在非线性的全连接层中,输入$x$也具有零均值和方差$\gamma^2$,我们此时期望输出$o$与输入$x$的均值方差保持一致(最重要的数值稳定性)即具有零均值与方差$\gamma^2$,经过数学推导可得$n\mathrm{in} \sigma^2 = 1$。在反向传播中运用相同的推论(此部分较复杂),我们希望梯度的方差也保持不变,因此$n\mathrm{out} \sigma^2 = 1$。因此,折中方案即令$\sigma^2 = \frac{2}{n{in}+n{out}}$。
注意这并不代表一定是正态分布采样,实际上主流有两种方式采样,一种是正态分布采样,一种是均匀分布采样,等价于值域$U\left(-\sqrt{\frac{6}{n\mathrm{in} + n\mathrm{out}}}, \sqrt{\frac{6}{n\mathrm{in} + n\mathrm{out}}}\right)$。
五. 深度学习计算
1. 层和块
块中包含多个层或块,为了复用等操作,均继承自nn.Module。
顺序块是一种特殊的块,它内部的层链条般顺序相连。
我们也可以自定义块,在块内部实现任意的数据流动,我们也可以在其中设置不反向传播的参数等。
2. 参数管理
2.1 获取参数
获取全部参数,无论哪个层次,均可通过下述方法获得当前层次包含的全部参数,因此我们可以粗或细粒度批量操作参数。
1 | for name, param in net.named_parameters() # 带名称 |
网络图如图所示,我们可以通过索引获得相应的参数,如我们访问第一个主要的块中、第二个子块的第一层的偏置项。
1 | rgnet[0][1][0].bias.data |
1 | Sequential( |
2.2 初始化
各种类型初始化,torch也会默认初始化
1 | nn.init.normal_(m.weight, mean=0, std=0.01) nn.init.zeros_(m.bias) |
3. 读写文件
state_dict():权重字典,包含名称(xx.xx.weight/bias)和值([1., 2., ...])
这要求我们先初始化好框架,在往框架中填参数。
1 | torch.save(net.state_dict(), 'mlp.params') # 保存权重 |
当然我们同样可以保存模型与参数。
4. GPU
只要所有的数据和参数都在同一个设备上, 我们就可以有效地学习模型。
1 | torch.device('cpu'), torch.device('cuda:1') |
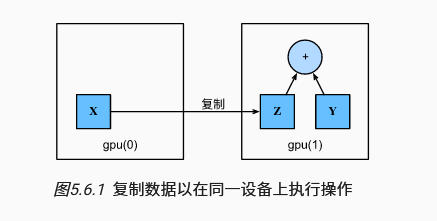
1 | x.cpu() # gpu -> cpu |
- 我们可以指定用于存储和计算的设备,例如CPU或GPU。默认情况下,数据在主内存中创建,然后使用CPU进行计算。
- 深度学习框架要求计算的所有输入数据都在同一设备上,无论是CPU还是GPU。
- 不经意地移动数据可能会显著降低性能。一个典型的错误如下:计算GPU上每个小批量的损失,并在命令行中将其报告给用户(或将其记录在NumPy
ndarray中)时,将触发全局解释器锁,从而使所有GPU阻塞。最好是为GPU内部的日志分配内存,并且只移动较大的日志!
六. 卷积神经网络
我们若对图像也采用同样的全连接层,则每个输出值要收到所有输入像素的信息,这样参数开销是巨大的。

1. 计算机视觉的两大特性
- 平移不变性(translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。
- 局部性(locality):神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。
2. 卷积层
2.1 平移不变性
这意味着检测对象随输入的平移,应该仅导致隐藏表示H的平移,即在(i,j)位置的输出像素和在(a, b)位置的输出像素所使用的参数应当是相同的,即参数不依赖于(i,j)的值。

2.2 局部性
划定一个范围,卷积核只看范围之内的内容,而忽视之外的内容。
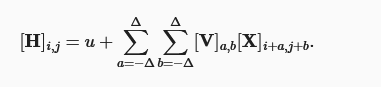
2.3 通道
图象是三维的,隐藏表示也最好用三维向量,换句话说,对于每一个空间位置,我们想要采用一组而不是一个隐藏表示。这样一组隐藏表示可以想象成一些互相堆叠的二维网格。 因此,我们可以把隐藏表示想象为一系列具有二维张量的通道(channel)。 这些通道有时也被称为特征映射(feature maps),因为每个通道都向后续层提供一组空间化的学习特征。
考虑到输入的第三维度和输出的第三维度,我们的卷积核(卷积层的参数)拥有四个维度。
其中隐藏表示H中的索引d表示输出通道,而随后的输出将继续以三维张量H作为输入进入下一个卷积层。 所以,该公式可以定义具有多个通道的卷积层,而其中V是该卷积层的权重。
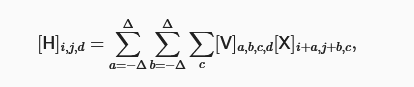
2.4 归纳偏置
上述的图像假设均为先验知识,若不符合归纳偏置,则效果可能会很差,即用归纳偏置换更少的参数与运行训练效率。
2.5 图像卷积
在卷积神经网络中,对于某一层的任意元素,其感受野(receptive field)是指在前向传播期间可能影响计算的所有元素(来自所有先前层)。
我们可以从数据中学习卷积核的参数。
2.6 关键参数,填充和步幅,输入输出通道
- padding: 一般为保持输入和输出的长宽相同(
stride=1),因此通常填充方式为。做padding的目的是防止边缘信息丢失。

- stride: 用于减小输出的长宽,通常而言,步长为n,我们的输出长宽均除以n。

- in, out: 输入输出通道,卷积核拥有参数
2.7 1x1 卷积核
作用于同一个位置的不同通道,相当于在通道维度上的全连接层,通常用于调整网络层的通道数量和控制模型复杂性。
3. 池化层
通常当我们处理图像时,我们希望逐渐降低隐藏表示的空间分辨率、聚集信息,这样随着我们在神经网络中层叠的上升,每个神经元对其敏感的感受野(输入)就越大。
而我们的机器学习任务通常会跟全局图像的问题有关(例如,“图像是否包含一只猫呢?”),所以我们最后一层的神经元应该对整个输入的全局敏感。通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有优势保留在中间层。
池化层没有可学习参数。
3.1 目的
- 降低卷积层对位置的敏感性,相邻位置的值被综合为一个值
- 降低对空间降采样表示的敏感性。
3.2 最大池化和平均池化
torch默认步长等于窗口大小。
- 对于给定输入元素,最大汇聚层会输出该窗口内的最大值,平均汇聚层会输出该窗口内的平均值。
- 汇聚层的主要优点之一是减轻卷积层对位置的过度敏感。
- 我们可以指定汇聚层的填充和步幅。
- 使用最大汇聚层以及大于1的步幅,可减少空间维度(如高度和宽度)。
- 汇聚层的输出通道数与输入通道数相同。
普遍规律:长宽维度逐渐降低,即全局信息越来越汇总,而通道数逐渐变多,即全局的不同特征被提取的越来越多
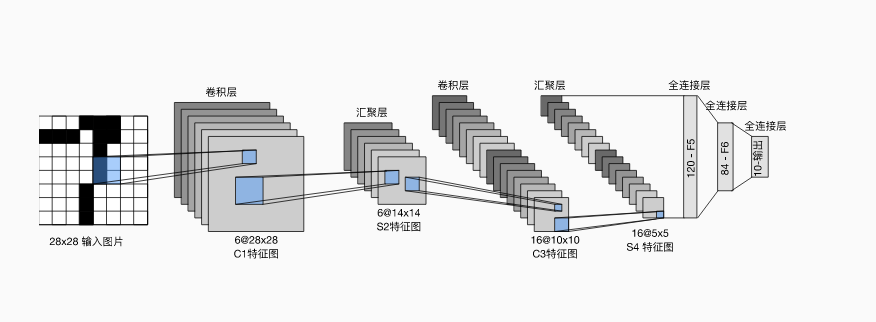
4. LeNet
卷积神经网络的开山之作,作者杨立昆;深度很浅,以全连接层汇聚。
七. 现代神经网络
1. AlexNet
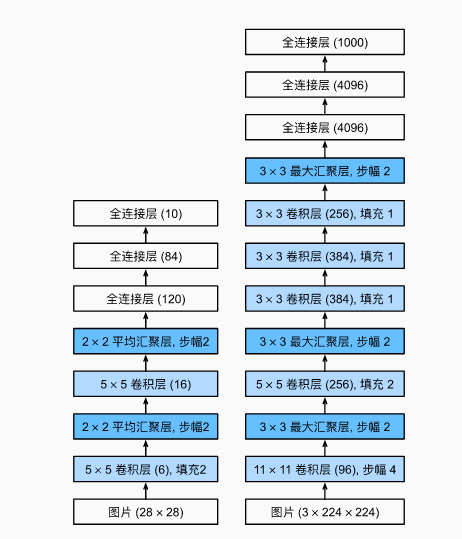
和LeNet比更深了,用的卷积核更大了,且激活函数使用reLU而不是sigmoid。
relu的优点:简单,不像sigmoid一般有复杂的求幂运算;正向时梯度为1,有效避免了梯度消失的问题,因此目前设计激活函数时均使用relu及其变种,如leakyrelu。
2. VGG
研究人员开始从单个神经元的角度思考问题,发展到整个层,现在又转向块,重复层的模式。
将多个层堆叠为一个块,一个块通常是可以复用的。
经典卷积神经网络的基本组成部分是下面的这个序列:
- 带填充以保持分辨率的卷积层;
- 非线性激活函数,如ReLU;
- 汇聚层,如最大汇聚层。

原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。 第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11。
一般激活函数和池化层由于无需参数,不称作一层。
卷积参数少,但是运算次数不会太少。
3. NiN
目前的设计模式都是通过一系列的卷积层和池化层提取空间结构,然后通过全连接层对特征的表征进行处理。但是在最后使用全连接层会放弃表征的空间结构(即使在深层长宽通常已经很小),因此NiN提出,可以在每个像素的通道上分别使用多层感知机,即的卷积核。
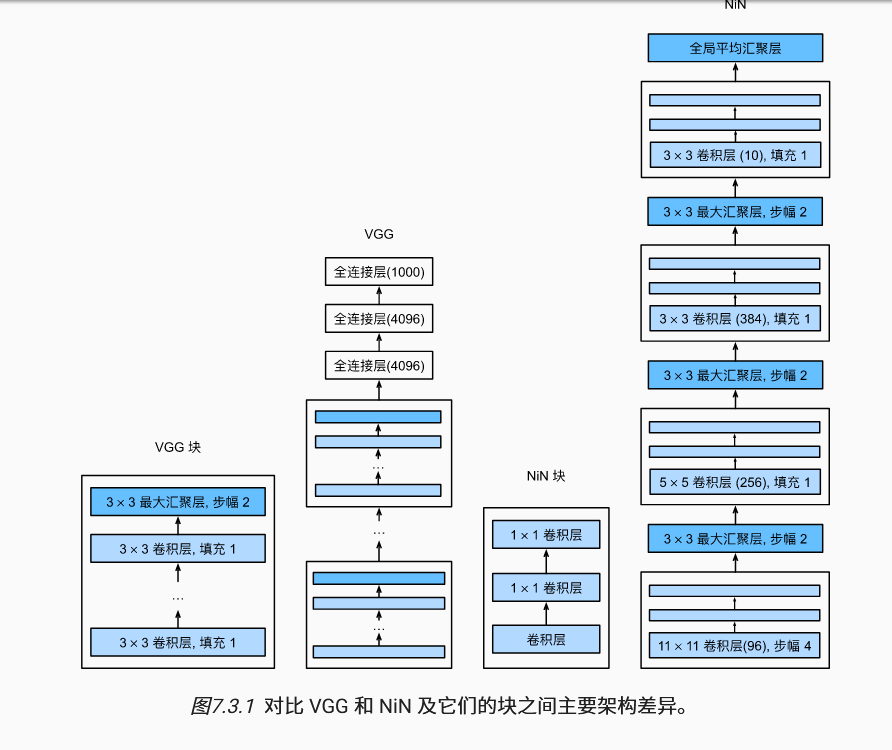
最后通过一个全局平均池化层,将每个通道的长和宽下采样到。
4. 含并行连结的网络(GoogLeNet)
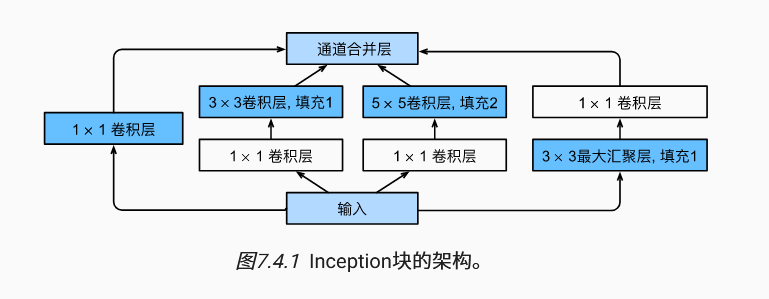
它们可以用各种滤波器尺寸探索图像,这意味着不同大小的滤波器可以有效地识别不同范围的图像细节。 同时,我们可以为不同的滤波器分配不同数量的参数。

GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。








