『机器学习系统』OpenMLSYS——阅读笔记1
『机器学习系统』OpenMLSYS——阅读笔记1
❀目录❀
前言
OpenMLSYS电子书链接。本书阅读于24年暑假,每天上午一章节,随阅读随记录笔记,记录的不详尽或复制粘贴原文之处敬请谅解。By the way,当时正处于没有一个offer的痛苦阶段,已经考虑转行做深度学习系统,进而阅读了这本书。
平心而论,该书电子版用的和《动手学深度学习》一样的模板,但内容质量差距较大(勿喷)。不过MLSYS近年来才起步并仍在发展,作者愿意总结知识并著作已经不可多得,这仍然是我最推荐入门机器学习系统的好书~
AI编译器与前端技术
计算机求导的方法
手动微分:人工计算表达式
数值微分:无穷小逼近,会产生截断误差;浮点数运算,会产生舍入误差
符号微分:不复用产生的变换结果,存在表达式膨胀问题

自动微分(机器学习框架使用):将计算机程序中的运算操作分解为一个有限的基本操作集合,且集合中基本操作的求导规则均为已知。在完成每一个基本操作的求导后,使用链式法则将结果组合得到整体程序的求导结果。我们将着重介绍自动微分。
- 前向自动微分:构建计算图,边前向传播,边时刻计算中间变量对输入的导数。最后得到,每个输出对单个输入的导数。
当我们对一个函数求导,想要得到的是该函数的任意输出对任意输入的偏导集合,因此经过多个上述步骤,得到一个雅可比矩阵。
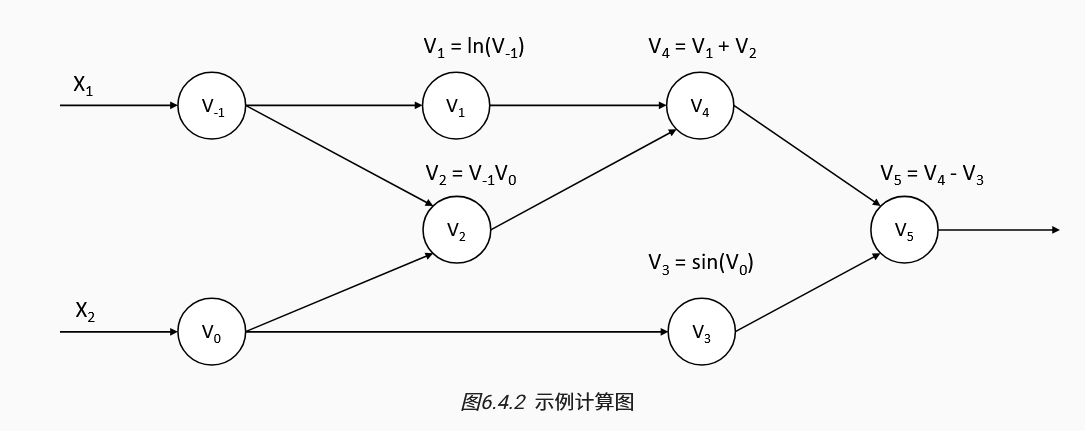
反向自动微分:先前向传播,记录中间变量与依赖关系,再反向传播计算最终输出y对各个中间变量的导数。最后得到,单个输出对所有输入的导数。
这种模式是机器学习系统中常见的,因此通常采用反向自动微分。反向涉及到对某变量梯度的累加,如下图的V0,在V3计算中依赖,在V2计算中依赖,因此第二个$\bar{V_0}$的计算需要与第一个$\bar{V_0}$的计算相加!
自动微分的方法——拆成多个原子操作:
- 基本表达式法
- 操作符重载(Pytorch)
- 代码变换法ST(MindSpore)
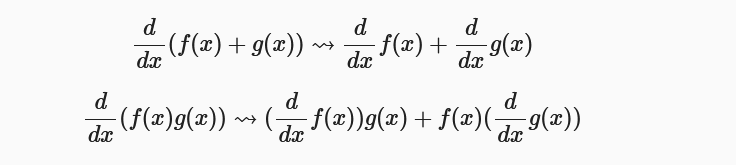



静态分析与类型系统
类型系统:类型系统用于定义不同的类型,指定类型的操作和类型之间的相互作用,其功能为:正确性,安全性,优化,抽象。python是动态强类型,但由于其解释执行的方式,运行速度往往较慢。若想要生成运行高效的后端代码,后端框架需要优化友好的静态强类型中间表示。需要将Python前端表示转换成等价的静态强类型中间表示,以此给用户同时带来高效的开发效率和运行效率,例如Hindley–Milner(HM)类型系统。
静态分析:对中间表示进行处理分析,并且生成一个静态强类型的中间表示,用于后续的编译优化、自动并行以及自动微分等。
编译器后端与运行时
计算图优化
通用硬件优化:与特定硬件类型无关,核心是子图的等价变换,在计算图中匹配特定的子图结构,找到目标结构后,通过等价替换方式,将其替换为更优的子图结构。
目的:计算更密集,减少低效内存访问
计算密集型算子,访存密集型算子。通常相伴出现,可以合并。
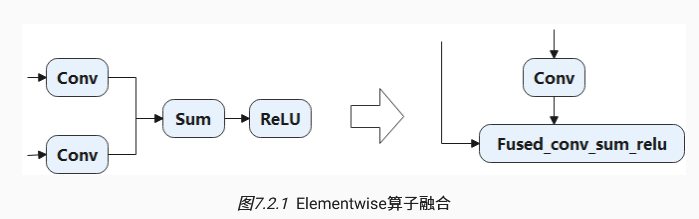
自动算子生成技术:算子拆解,算子聚合,算子重建。
特定硬件优化:往往某些硬件不支持一些算子,或有一些额外性质,比如硬件指令的限制,数据排布格式的限制等。
算子选择
为计算图上的每个算子分配在设备上执行的算子,往往计算图的每一个节点都有一组设备算子与之对应
获取算子信息:数据排布格式 + 计算精度
数据排布格式:矩阵乘法的第二个矩阵,最好是按列优先存储,如此可通过访问连续内存的方式加快数据访问速度。计算机对张量的存储方式为展平成一维!
默认的数据排布格式(图像):NCHW, NHWC
问题:访问元素时内存不连续,而输入的数据往往大于计算部件一次计算所容纳的最大范围,因此需要切片分批计算,增大访存开销。
解决:块布局格式,硬件加速指令
数据精度:单精度(float32),半精度(float16)
算子信息库:一个硬件上支持的所有算子的集合定义为该硬件的算子信息库。算子选择过程就是从算子信息库中选择最合适算子的过程。
选择过程:选择硬件设备,根据排布格式与数据类型选择合适的算子。由于不同硬件支持的算子不一,存在算子选择的算子与用户预期的类型不一致的现象,此时会降精度或其他处理。

内存分配
显存称为Device内存,CPU内存称为Host内存。CPU和硬件加速器的控制器无法直接访问对方的内存。该步骤即为输入输出分配内存地址。
为输入,权重,输出分配内存地址:输入往往是上一算子的输出,因此可将上一算子的输出地址共享到该输入,可避免冗余拷贝与空间占用。因此,需要分配的内存有三种类型:整张图的输入,算子权重,算子的输出
内存的管理方式:
内存池:申请一定数量的内存块留作备用,当程序有内存申请需求时,直接从内存池中的内存块中申请,当程序释放该内存块时,内存池会进行回收并用作后续程序内存申请时使用。
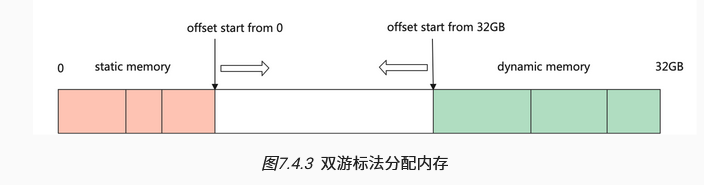
双游标法分配:一侧分配生命周期较长的权重张量,一侧分配生命周期较短的算子输出张量。通过这种方式,只需要从设备上申请一次足够大的内存,后续算子的内存分配都是通过指针偏移进行分配,减少了直接从设备申请内存的耗时。
- 内存复用:
- 定义:已使用结束的算子输出的内存可用于后续算子输出的内存分配。
- 内存生命周期图:横坐标生命周期,纵坐标所占内存区域。如何分配更多矩形!是NP完全问题!

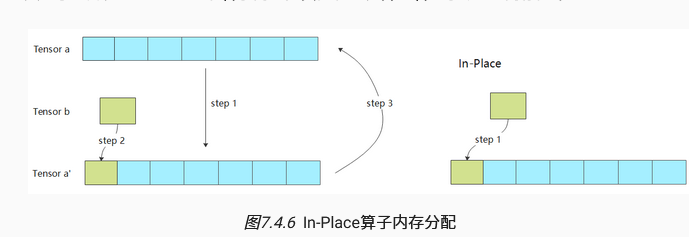
- 内存分配优化手段:内存融合(对一些特殊的算子,分配连续的设备地址);In-Place算子(Pytorch有,一些Bug产生的万恶之源),即原地操作,无需新开地址拷贝一份张量操作,而是直接对原内存地址相应位置操作。
计算调度与执行
单算子调度:运行时算子被逐个执行,无法上下文优化,无法并行计算,不采用!
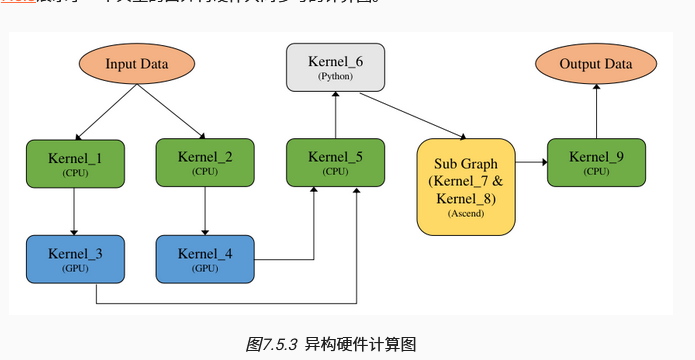
计算图调度:一张计算图可以由运行在不同设备上的算子组成异构计算图
CPU算子:C++语言编写的在Host上执行的算子,性能取决于是否能够充分利用CPU多核心的计算能力。
GPU算子:将GPU Kernel诸葛下发到GPU设备上并行加速,AI芯片上具备大量的并行执行单元。
NPU算子:支持将部分或整个计算图下沉到芯片中完成计算,计算过程中不与Host发生交互,因此具备较高的计算性能。
Python算子:Python解释器解释执行,与CPU算子类似
- 并发执行:下图明显可并发执行,但需注意一些并发执行会引起副作用
交互式执行:框架的运行时根据计算图中算子的依赖关系,按照某种执行序(例如广度优先序)逐个将算子下发到硬件上执行
非异构计算图的执行方式:
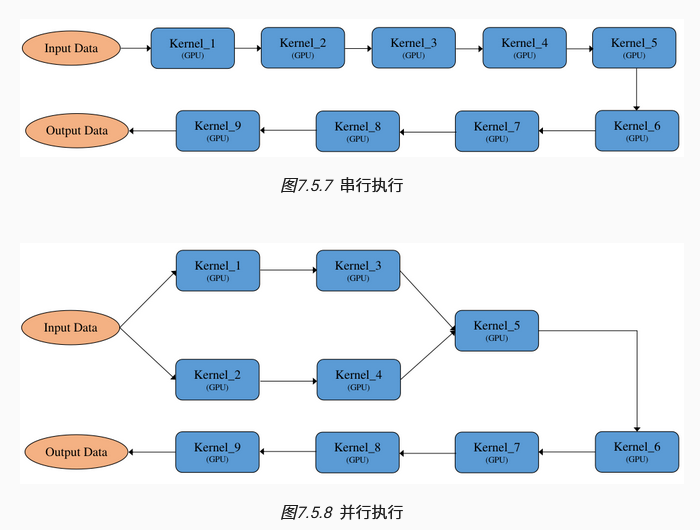
串行执行:广度优先
并行执行:按依赖关系展开
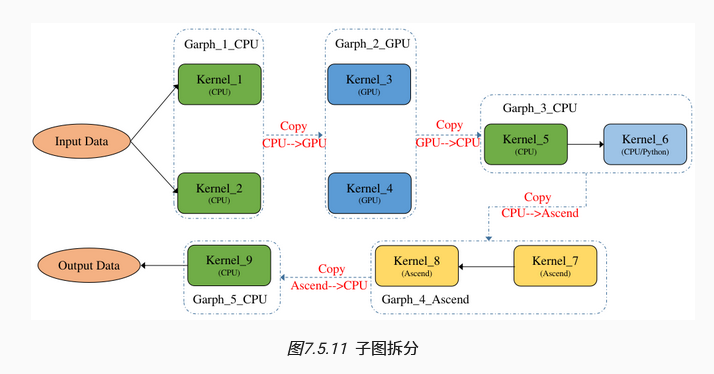
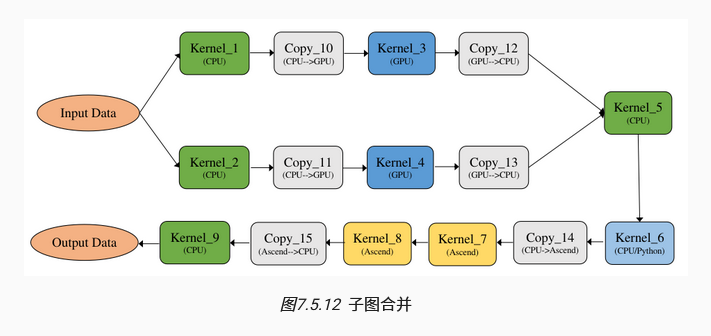
异构计算图的执行方式:首先将异构计算图切分为多个非异构计算图,进而引申两种执行方式。(通常默认是并行执行)
子图拆分执行:将切分后的子图分开执行,上一个子图的输出会传输给下一个子图的输入,并且需要将输入数据拷贝到本图device上。
子图合并执行:将多个子图合并,交接处插入设备拷贝算子,以实现不同设备算子数据传输,将整张图形成一个大的整图执行。
下沉式执行:将整个或部分计算图一次性调度到芯片上以完成全量数据的计算,避免了在计算过程中主机侧和设备侧的交互,因此可以获得更好的整体计算性能。
硬件加速器
硬件加速器的结构:存储单元(片上缓存)(寄存器文件+共享内存+L1L2缓存)+计算密集型计算单元(标量+向量+张量计算单元)
加速器编程:编程接口调用,算子编译器优化
编程接口使能加速器
- 算子库层级
- 编程原语层级
- 指令层级
算子编译器使能加速器
算子长尾问题:指在深度学习模型中,尽管大多数计算由常见的、常规形式的算子(如卷积、矩阵乘法等)完成,但仍然存在大量种类繁多的非常规算子。这些非常规算子的出现频率相对较低,但它们的总数和种类却在不断增加。
矩阵乘法加速的实践:
最基本:每个输出元素由一个线程计算,共M*N个线程
计算强度(计算指令数量/访存指令数量)优化:
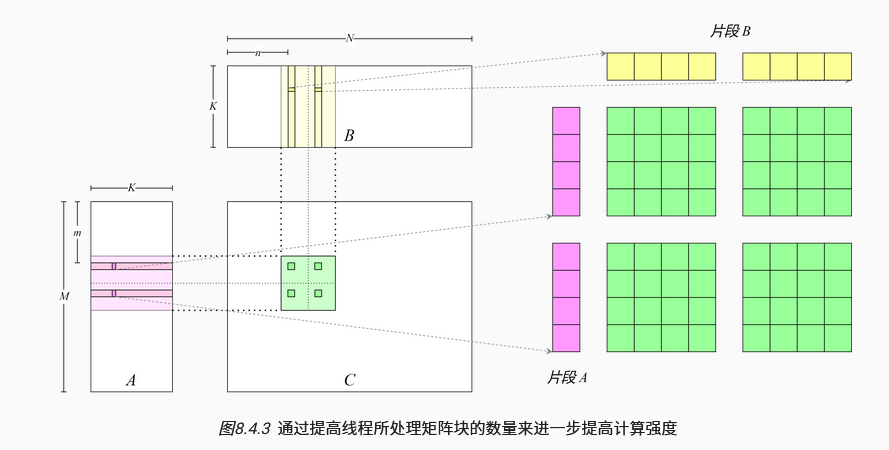
如果在K次循环的内积计算中一次读取矩阵A中的m个元素和矩阵B中的n个元素,那么访存指令为m+n条,而计算指令为2mn条,所以计算强度为$\frac{2mn}{m+n}$,因此可以很容易发现提高和会带来计算强度的提升。
实现:使用宽指令,一个128位的宽指令一次可以读取4个float数,因此现在可以将C划分为4*4的矩形块,每个线程处理一个矩形块的运算。进一步,一个线程可以处理多个矩形块的运算。
缺点:并行度大幅降低
使用共享内存优化(优化的核心并不在明面上的复杂度,而是合理利用并行与高速缓存):
观察:处理矩阵C同一行的线程x,y需要读取矩阵A中相同的数据。
对于每一个线程块,先集合所有线程将所需的矩阵元素读进共享内存,再分别从共享内存读取元素进行乘加法运算。
图中表述为:将$K$拆成$tileK$块,每块$\frac{K}{tileK}$个元素。使用外层循环读取每块的元素,使用内层循环计算当前子块的结果。
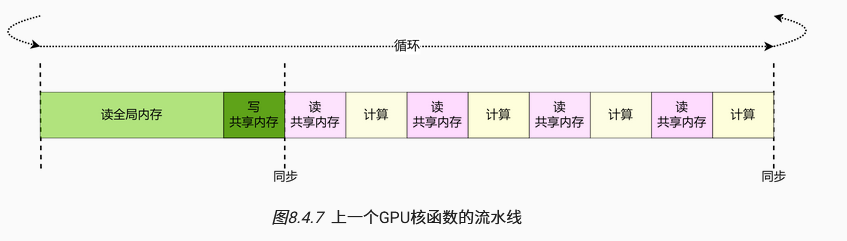
流水线优化:
前提:本次循环的整个内层循环过程中不依赖下一次循环的数据。
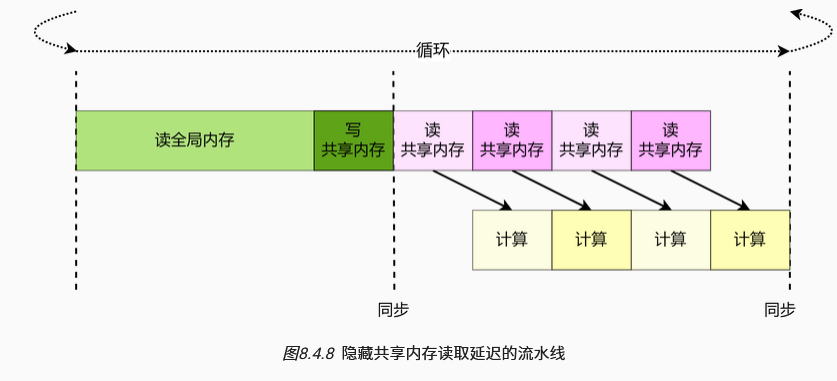
读共享内存的周期仍多于计算所用的周期,可通过一定方式隐藏对共享内存的访问,重新优化流水线降低读取延迟。
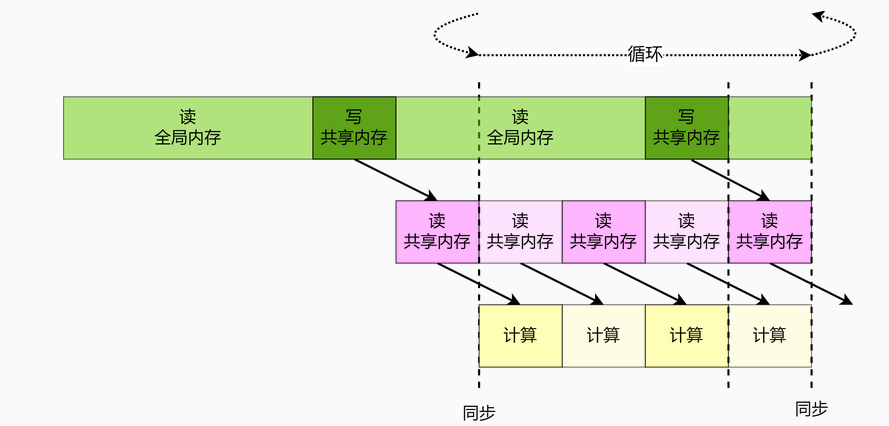
进一步,读全局内存时同样能做上述优化,从而实现隐藏全局内存读取延迟的目的。

数据处理模块
易用性:基于描述数据集变换的编程抽象提供编程接口与变换算子,数据集创建方式
高效性
数据读取:统一文件格式,并行化读取(
num_workers)数据计算(预处理):
底层架构层面:流水线并行,算子并行;异构计算(CPU+GPU),分布式(多服务器数据处理)
编译算法层面:AI编译层面的计算图优化,同将多个操作融合或调换顺序实现优化。
保序性:即在
shuffle的后续操作中,不能对数据的输出顺序有改变。通过不同进程间的connector队列实现。
模型部署
训练时模型 ➡ 推理时模型
ONNX(Open Neural Network Exchange)神经网络交换协议:将不同框架的模型使用中间语言统一表示
推理时优化:推理时一些层的行为改变,且权重参数皆为常数。算子融合,算子替换,算子重排。
✳模型压缩✳
模型量化:将权重与激活值从浮点数映射到整数(int8),实现存储上的压缩与推理上的加速,在输出层及某些层需要通过反量化将整数映射回浮点数。需要在模型精度与效率间达到平衡
QLoRA: 一种使用量化方案的LoRA,原LLM量化为4位(四位如何表达数值有很大讲究)后,再使用LoRA微调
模型稀疏(剪枝):
动机:过参数化,激活值特征图中能利用的有效信息相对于整张图占比较小
方法:将权重与激活值的某些强度较弱的值(绝对值大小)设置为0,0值所占的比例称为模型稀疏度。
结构化稀疏:在通道或者卷积核层面对模型进行剪枝。这种稀疏方式能够得到规则且规模更小的权重矩阵
非结构化稀疏:以对权重张量中任意位置的权重进行裁剪
稀疏策略:$预训练 —— 稀疏剪枝 —— 微调 / 训练 —— 剪枝 —— 训练 …$
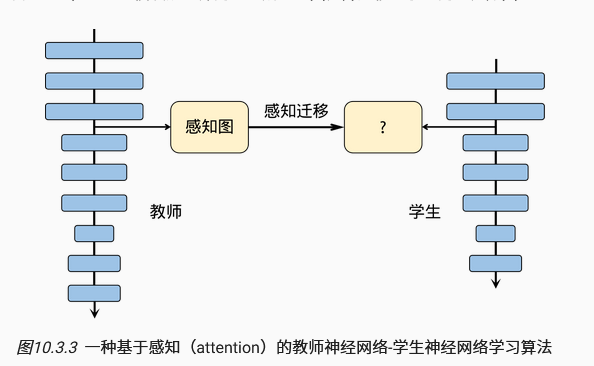
知识蒸馏(教师-学生神经网络学习算法):教师网络是训练好的网络,学生网络是待训练网络,通常参数更少。
方法1:同时令学生网络的结果接近真实标签结果与教师神经网络的分类结果
方法2:仅将教师网络的输出中提取有价值的信息与学生同步远远不够,还可以从中间结果(特征图)中挖掘信息与学生同步。


推理优化
并行计算:矩阵乘,拆成多个线程同步运算
算子优化:
硬件汇编指令优化:合理利用硬件寄存器,提升缓存命中率、优化汇编性能
算法优化:卷积的矩阵乘法优化
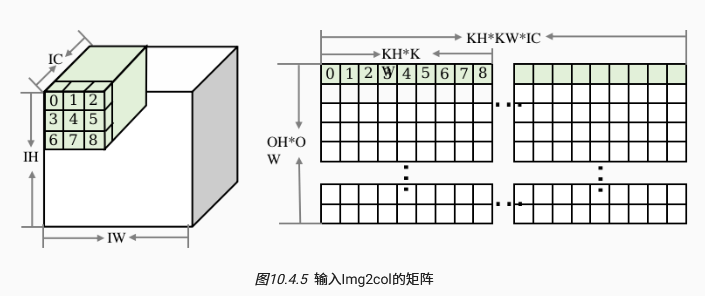
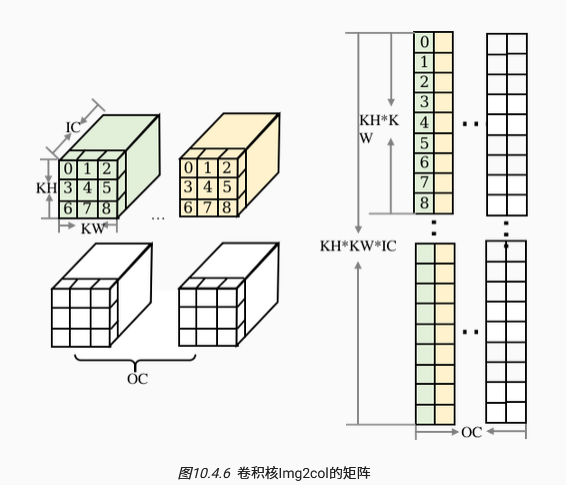
img2col:卷积的本质仍是矩阵乘法,具体而言,将输入与权重分别做重排,对输入而言,将$1IHIWIC$重排为$(OHOW)(KHKWIC)$,即将与卷积核运算的每个区域展开成一行,根据步长和填充,获得$OHOW$行:
对权重而言,将一个卷积核展开为权重矩阵的一列,共$OC$列,最后二者矩阵乘法,得到$OHOWOC$维度的特征图。
Winograd算法:简化卷积运算,减少非常量乘法运算,增加常量加法与乘法运算,使用中需要取舍。